
我先分享下我们小厂是怎么玩的
所有服务节点都接了 pinponit ,然后结合 kibana 收集的线上日志+traceid
分享几张今天新鲜出炉的 bug 图
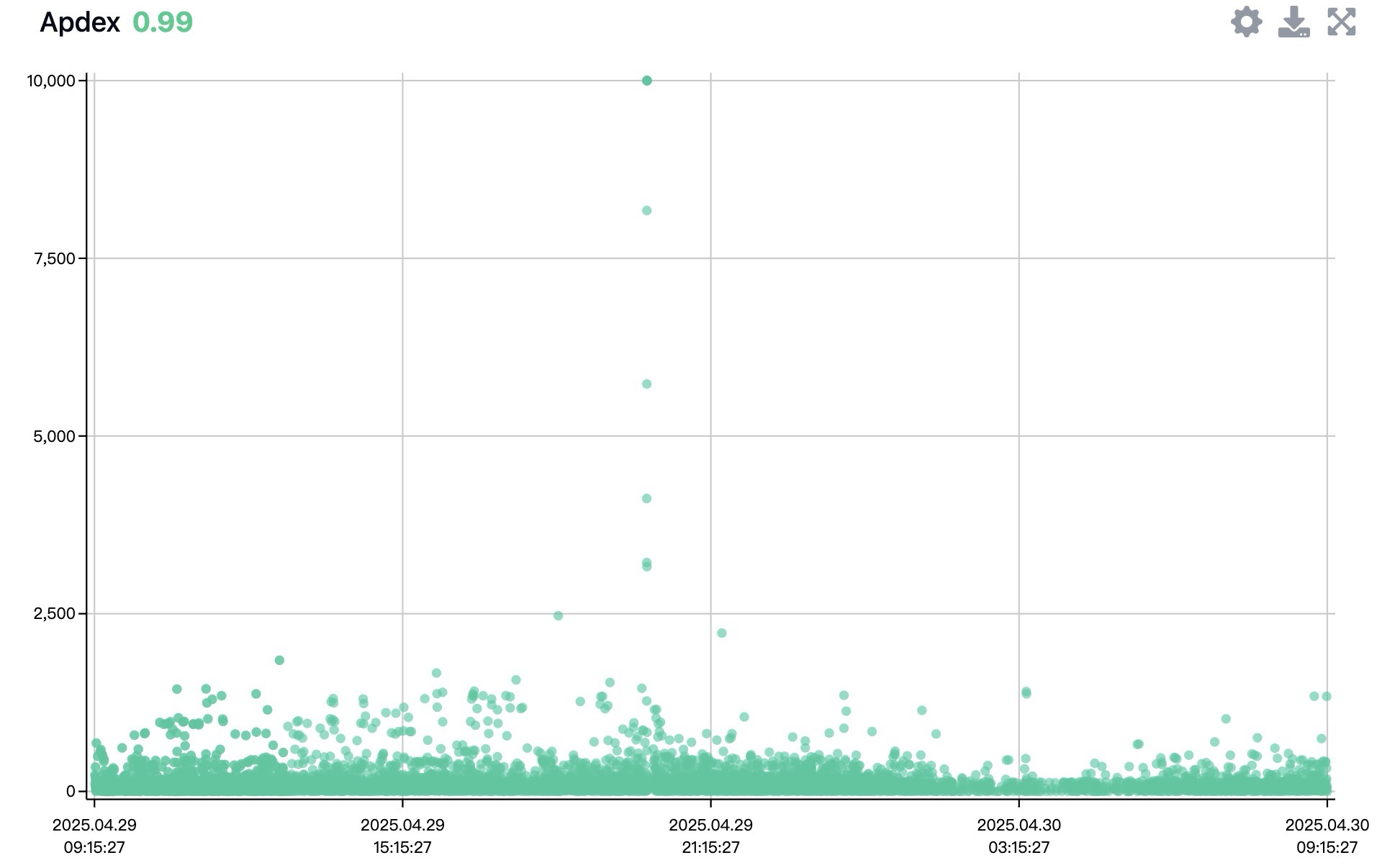
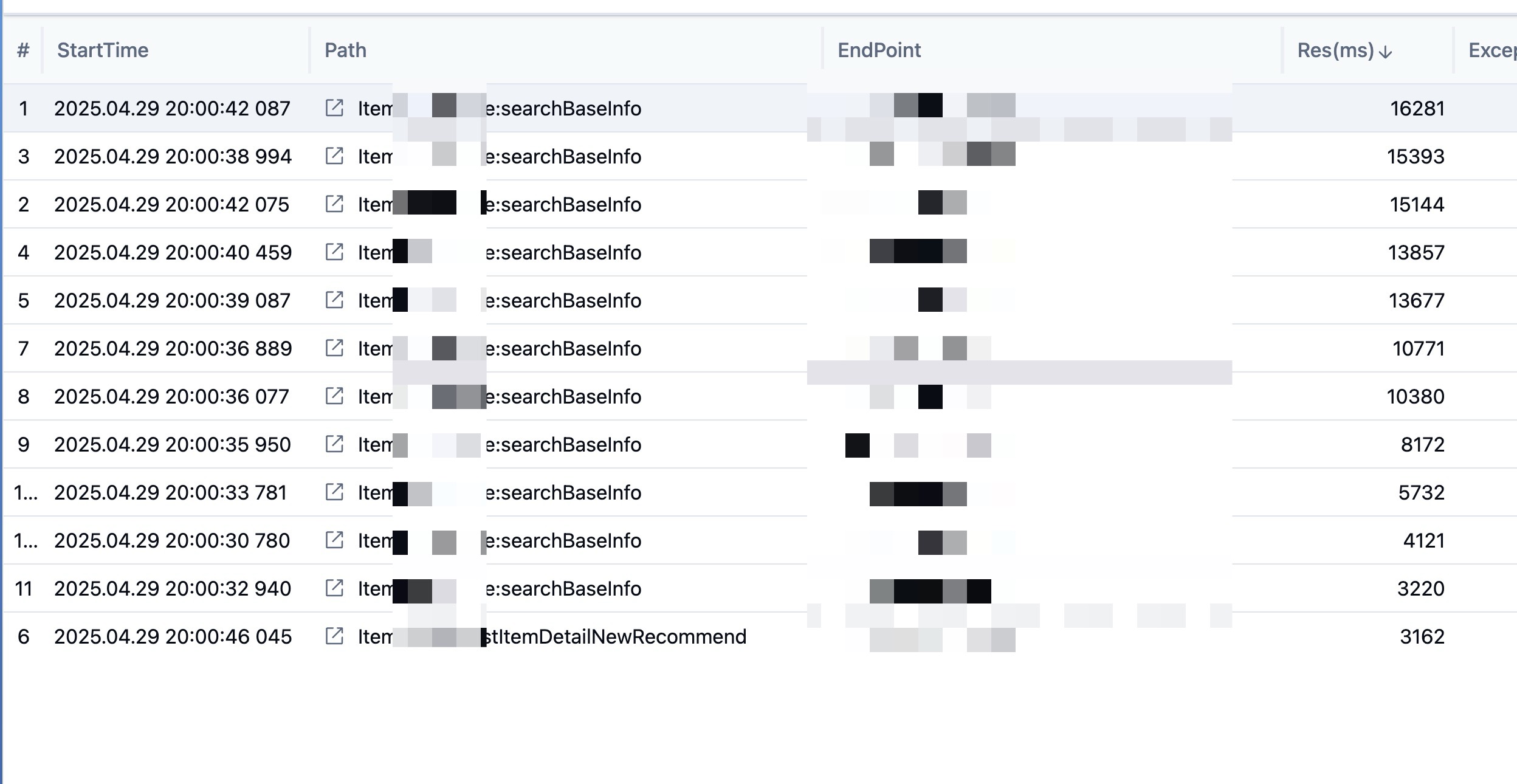
今天发现根据这个 pp 的日志就很快定位到有查全表的场!
第 1 条附言 · 5 天前
这个帖子还是很牛的,每个人都分享一种模式
这样每个都都有 N 种处理思想了
这样每个都都有 N 种处理思想了
 |
101
mbeoliero123 6 天前
@seth19960929 #58 小厂应该没有必要上 tracing 吧?只需要有 log id 串联就行?
|

 |
103
prosgtsr 5 天前 via iPhone
@whoami9426 压力拉满
|
 |
105
seth19960929 5 天前
@mbeoliero123 看需求
|
 |
106
gotkx 5 天前
啊,
第一步 ,上 sls ,获取全部请求的 trace_id ,和调用情况 第二步,上 arms ,查看整体的服务状态,可以直接拿第一步的 trace_id 追溯 第三步,上 mse 限流,查不出异常的接口和功能,直接限流 我一直以为大家都一样呢,看了下评论才知道。。。。 |
 |
108
iClass 5 天前 via Android
大厂没有同事 只有同行 还有某些同志 👯♂️
|
 |
109
huzhizhao 5 天前
外包仔路过
log 猜 测试环境尝试复现 本地 debug |

 |
112
starlion 3 天前
Prometheus + SkyWalking + grafana
|
 |
113
saltpi 3 天前
以前开发 iOS ,线上生产 App 崩溃,Xcode 打开就可以收到崩溃通知,点开具体版本,可以定位到具体崩溃的源码行和出现错误时的本地变量值
|



 |
119
pulutom40 1 天前 via iPhone 大厂也没这么牛的工具,坐标百度,bug 定位全靠 grep 。什么你问线上几千台机器怎么 grep ?那就写个脚本把命令发到每天机器上去 grep 。结果 grep 命令过滤没写好,日志拉太多,把机房网络 io 干满了,喜提新事故一个。
不信你去百度面试看看,上来就是问 diff awk gerp 命令,入职前我还纳闷,这些破命令问这么细干嘛,入职后才知道,原来不精通这些命令,根本找不出 bug 在哪。 |
 |
120
yrzs 1 天前
OTEL 全链路追踪+EFK
|
|
122
pulutom40 1 天前 via iPhone
@5261 定位系统不存在的,线上服务器操作系统 centos4 ,线上 php 版本 5.4 。这些东西年纪都基本上跟我一样大了,你觉得可能有啥牛逼东西么。大厂只是大,不代表技术有多牛
|
|
123
pulutom40 1 天前 via iPhone
日志系统越大的公司越不愿意做,再说一个我呆过的公司,月活用户亿级别。早期日志系统是 elk 那一套,光日志系统,es 的年维护成本是十亿+人民币。
然后在降本增效的社会背景下,日志降本第一个被提出来,为此基础平台部先做了 es 魔改加了各种压缩算法,但是收效甚微。于是又把 es 换成了 ck ,但成本也没少多少。再后来又把日志成本分摊到各个部门,要求各个部门自己治理。但是大家能怎么治理,而且迁到 ck 后使用体验已经很差了,于是各部门纷纷下线日志收集。最终日志也和百度变成一样的,查问题全靠 grep 。 这样相当于绝大部分部门直接下线了日志系统,日志成本治理顺利完成,在老板看来,大家 bug 照样改,但是研发成本每年降低 xx 亿 |
 |
124
5261 OP |
 |
125
littlesky87906 9 小时 51 分钟前
@weilai99 占用资源并不算多,4c16g 就妥了。访问量 1000rps 左右
|