
我先分享下我们小厂是怎么玩的
所有服务节点都接了 pinponit ,然后结合 kibana 收集的线上日志+traceid
分享几张今天新鲜出炉的 bug 图
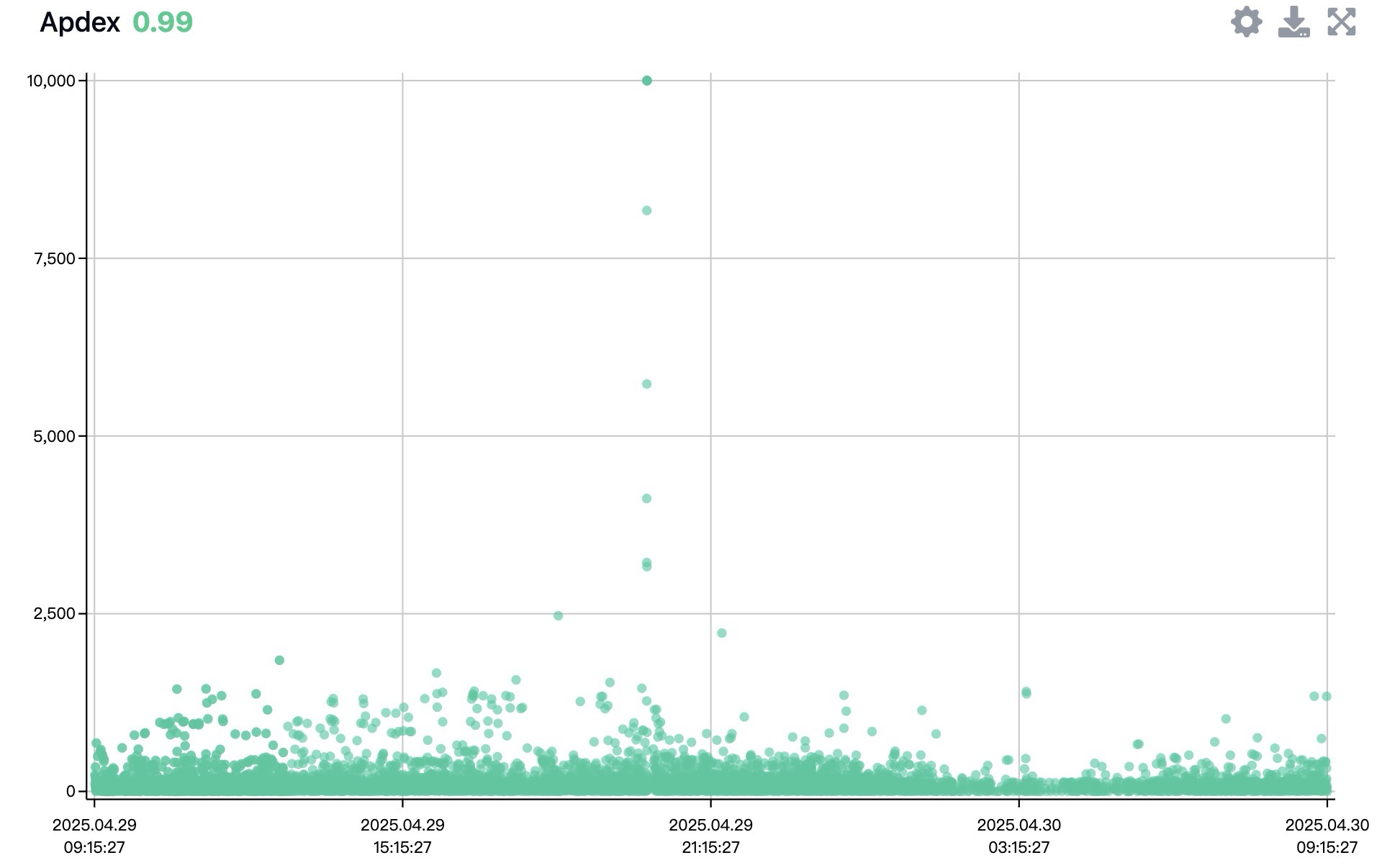
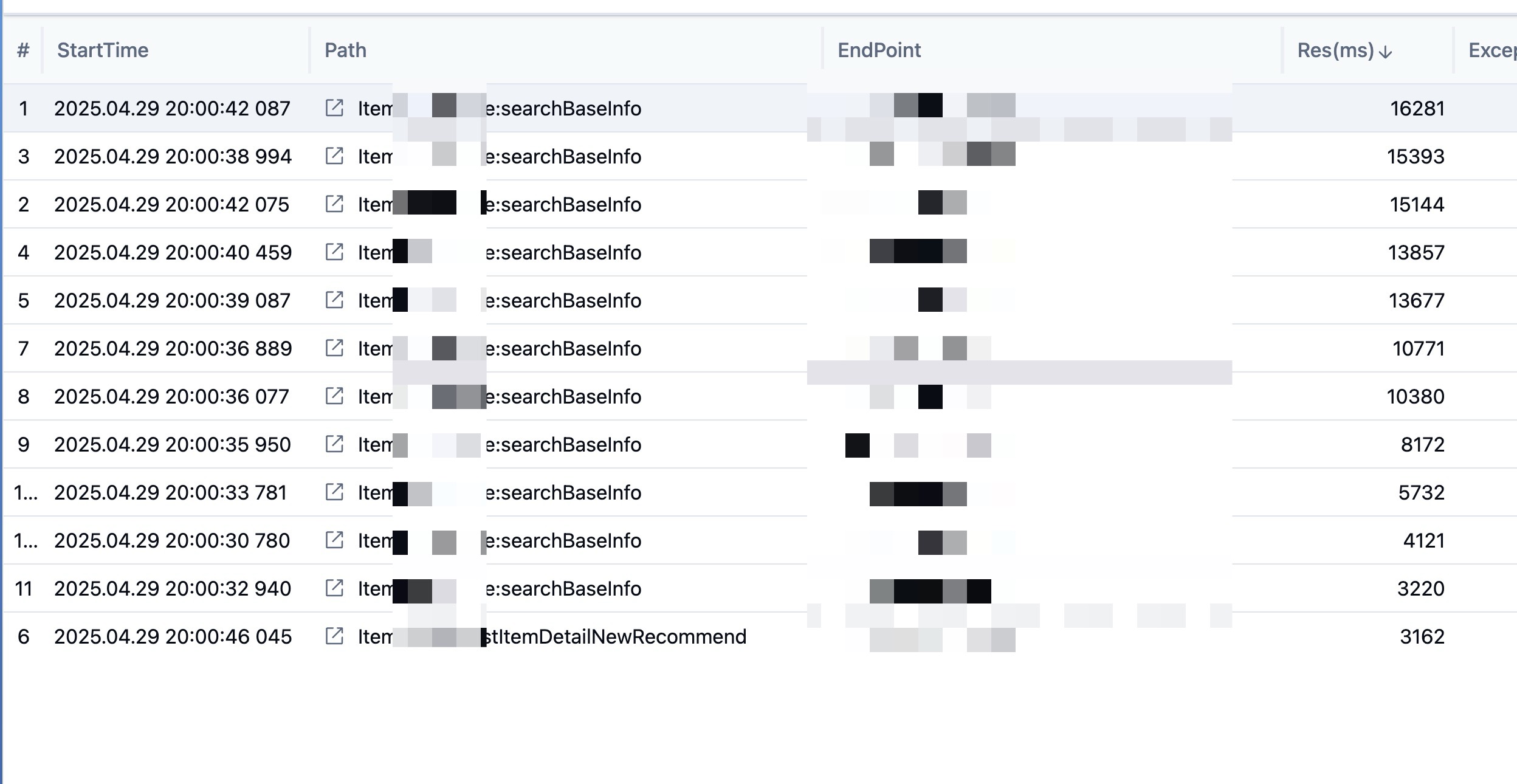
今天发现根据这个 pp 的日志就很快定位到有查全表的场!
第 1 条附言 · 5 天前
这个帖子还是很牛的,每个人都分享一种模式
这样每个都都有 N 种处理思想了
这样每个都都有 N 种处理思想了
 |
1
opengps 7 天前 小厂未必用得上你的这么高级的工具。分析办法全靠经历事故来积累经验
|
 |
2
Pythoner666666 7 天前 日志收集 + 监控,剩下的全靠个人经验了
|
 |
3
darksword21 7 天前
printf
|
 |
4
5261 OP @darksword21 大佬啊
|
 |
5
ala2008 7 天前 小公司 tail -f xxx.log 啊
 |
 |
6
littlesky87906 7 天前
sentry
|
 |
7
7gugu 7 天前 后端就是靠 TraceId 看链路+日志上报
web 就是看 JS 堆栈+日志上报来分析 |
 |
8
MuSeCanYang 7 天前 23333 ,在全球五百强。 我们现在都没用上你这一套东西。
|
 |
9
Ljxtt 7 天前
推荐之前看到的一篇文章 [线上故障应急处理:4 年多 on call 经验总结]( https://jt26wzz.com/posts/0007-online-firefighting-real-world-lessions-from-4-years-on-call/),虽然不是什么具体的工具,但感觉思路还是可以的。
|
|
11
5261 OP @littlesky87906 好,晚点我也去看下
|
|
12
Ljxtt 7 天前 @Ljxtt 我去,怎么多了个空格,[线上故障应急处理:4 年多 on call 经验总结]( https://jt26wzz.com/posts/0007-online-firefighting-real-world-lessions-from-4-years-on-call/)
|
 |
13
ssiitotoo 7 天前
skywalking
|
 |
14
jimmzhou 7 天前 var_dump();die; phper 就是任性
|
 |
15
tpopen 7 天前
tail -f xxxx | xargs grep xxx
|
 |
16
dddd1919 7 天前 以前写 ruby ,都是直接生产 rails console 执行代码调试🤣主打一个胆大心细
|
 |
17
pkoukk 7 天前
kibana + trace_id 搜就行了,没空搞这些花里胡哨的,开发自己用的工具不算 KPI ,能用就行,懒得搞
|
 |
18
msg7086 7 天前 我们都是 tail -f 大法
|
 |
19
kevinxzhao 7 天前
大盘监控 + 链路追踪 + 查日志。
|
 |
20
darkengine 7 天前
tail -f, grep 😂
哦不对,我们不是大厂 |
 |
21
lawler 7 天前
splunk
|
 |
22
wxw752 7 天前 就以我们公司这点微服务体量,闭着眼睛都能知道大概哪里的问题
|
 |
23
wahaha3010 7 天前
监控+指标+数据+日志
|
 |
24
0x49 7 天前 楼上都是大佬,我们小小小公司项目发现问题,都靠客户...
客户不反馈=项目无 bug,反馈了不能复现出来,就不算问题. |
 |
25
Leon777 7 天前 我们小厂有时候要测试开发产品三方会诊才能确定这到底是 feature 还是 bug 😂
|
 |
26
foolishcrab 7 天前 via iPhone
这种代码问题导致的单点故障基本上依靠基建都是非常好排查的。
稍微难一点的是上下游变更导致离变更节点非常远的地方异常,这种基本是排查时间点附近的变更并结合业务专家经验来看。 最难的是变更后很久才能发现的业务一致性问题,基本就靠人力慢慢推理了 |
 |
27
nevermoreluo 7 天前
小厂,先大致确定问题服务是哪组,开发查日志,问题严重需要联系运营找群里论坛里看有没有用户发复现操作,测试尝试复现。
拿到大致复现逻辑或者可能根本无法复现的,运维切备用线路,也可能问题太大先切,看运维和运营把控。 如果没有备用线路,看情况问运营争取关掉外网网关一段时间。至于该不该有备用是事后开会讨论的事。 如果日志查不出来就再拿其他工具分析旁路分析 tcpdump ,proc, gstack ,实在不行就找写这部分代码的开发一起调试吧,反正用户已经切备用线路了。 动态语言可以上一些 console ,或者一些内部接口实现一些简单的 runtime script ,例如动态读取一个脚本文件 or 语句执行 静态语言例如 c++就 ci 再 build 个 RelWithDebInfo ,该调试调试,该 dump 就 dump 当然上面说的运维+测试+看日志的+写这部分代码的人,可能都是你( bushi |
 |
28
lepig 7 天前 vim 20250430.log
/errorText (回车) 找吧就... |
 |
29
1yndonn3u 7 天前 多说无益,先摇人。
|
 |
30
whoami9426 7 天前
虽然不是大厂,但也是我们公司内部开源出来的一种解决方案,实时的告警和全链路的追溯 https://github.com/GuangYiDing/exception-notify
|
 |
31
Greendays 7 天前
太高级了,看不懂(
|
 |
32
js2854 7 天前
直接腾讯云低频 CLS 不香么
|
 |
33
server 7 天前
跟着赶脚走
|
 |
34
chenyu0532 7 天前
就我自己用 frebase 么。。。
|

 |
36
freeup 7 天前
一般就看堆栈,异常类型,结合函数签名与功能,与最近相关改动,加上点日常经验,基本能解决 99%的问题
|
 |
37
imokkkk 7 天前
一般的问题就是群里监控告警,一般告警的时候会携带异常的采样,拿到 traceId 之类的去阿里云 SLS 查日志。
严重的问题就是 GOC 拉群摇人 |
 |
38
DUNAI 7 天前
先看大动脉有没有被裁
|

|
40
whoami9426 7 天前
异常直接到群里自动分析堆栈并找到代码的提交人 at 对应的人处理并附带上全链路的日志
 |
 |
41
Lockroach 7 天前
tail -f xxx.log | grep xxx --color
|
 |
42
8355 7 天前
全链路+网关+告警啊
|
|
43
whoami9426 7 天前
|
 |
44
VVVYGD 7 天前
skywalking + 自研类似 skywalking 项目 + EBPF + 知识图谱系图数据资产
|
 |
45
vincentWdp 7 天前
一边复现, 一边看日志
|
 |
46
craftsmanship 7 天前 via Android
这帖子看得我笑中带泪啊🥹
|
 |
47
Sanow 7 天前
arthas 直接排查
|
 |
48
epicSoldier 7 天前
less xxx.log;
xx%; page down... |
 |
49
layxy 7 天前
日志+监控基本能够排查绝大部分故障
|
 |
50
yc8332 7 天前
接口响应时间+服务器的各种监控告警。。
|
 |
51
lilyou 7 天前
@whoami9426 q 请问这个怎么实现的
|
 |
53
billbob 7 天前
docker service logs -t app 打开,测试你再点一下
|
 |
54
crackidz 7 天前
线上直接 debug
|
 |
55
declandragon 7 天前
php lumen 框架
error handle 写日志 filebeat 收集上报 elk python 每 20 分钟定时统计,有错误发通知到群里 |
|
56
whoami9426 7 天前
@lilyou readm 中有介绍原理,主要是通过 @AfterThrowing
|
 |
57
seth19960929 7 天前
小厂直接上阿里云的 tracing 就行了, 很便宜, 全量 30 天存储一个月几千块
 https://www.shiguopeng.cn/posts/2024032815/ 不过上了之后, 又发现一个别的 bug >_ |
|
58
seth19960929 7 天前
一个在用的方案:
日志: k8s 容器 (写文件 | 标准输出), 阿里云 SLS 自动收集到对应的服务 链路: 使用标准的 opentelemetry 协议上报到 阿里云 ARMS, 如上图 报警: 总共三层 日志(SLS)聚合, tracing 聚合(p95, HTTP 错误), gateway 错误 gateway (这一层一定要加, 曾经吃过亏, 服务进程卡死, 日志不收集, tracing 也不上报了, 直到 gateway 层 500 错误很多)  |
 |
59
supuwoerc 7 天前
less run.log :G :?error
|


 |
61
spritecn 7 天前
@seth19960929 SLS 是不差钱的公司才用得起的
|
|
62
5261 OP @seth19960929 我们有小项目是接的阿里云的日志系统,总感觉没有自己搭建的 elk 灵活
|
 |
63
njmaojing 7 天前
1 、站点监控:每个服务 api 探活
2 、日志堆栈告警 3 、链路监控,模拟用户真实请求 先靠这些主动发现问题,具体怎么处理问题,就是 tail -f ,pinpoint ,查看埋点之类的     |
 |
64
weilai99 7 天前
@littlesky87906 自托管的 sentry 57 个容器,是认真的吗?
|
 |
65
luciankaltz 7 天前
说存 ELK 的能问下数据规模和成本吗(
|
 |
66
lu5je0 7 天前 via Android
各种监控埋点
|
 |
67
lizhengg 7 天前
前端+app 一套探针探测组件性能上报,后端 Apm 探针,堆栈链路分析工具,云 LTS 日志存储检索,基础设施性能,中间件慢日志,队列堆积监测等,可观测性系统加混沌工程定期测试,每个月应急演练。
|
 |
68
R77 7 天前
小厂,接口,服务器监控,人肉 log 分析
|
 |
69
AmaQuinton 7 天前
kubectl -n namespace logs -f pod-name --since=1h
|
 |
70
pigf 7 天前
@MuSeCanYang 尾大不掉
|

 |
72
BestPix 7 天前
@whoami9426 感谢分享,很有用!
|
 |
73
proxychains 7 天前
journalctl -xeu myapp | grep -i err
|
|
74
5261 OP @luciankaltz 成本确实有点大,光 es 3 个节点 就要不少费用
|
 |
75
Grocker 7 天前
SLS
|
 |
76
NathanInMac 7 天前
最简单就 Sentry + SLS + OpenTelemetry
|

 |
78
qbmiller 7 天前
楼主用的 elk 那套吗。 loki 那套 看好多用的
|
 |
79
Youko 7 天前
arthas 挺好用
|
|
80
seth19960929 7 天前
@spritecn SLS 还挺便宜的, https://sls.console.aliyun.com/lognext/tools/calculator 100G 30 天保存, 一天 40 块
@5261 #62 没感觉有什么灵活的, 反正比自建省事, 毕竟 k8s 也用阿里云的 |
 |
81
Charlie17Li 7 天前
纵坐标是啥,我们都是 SLS 查关键字
|
 |
82
tudou1514 7 天前
牛逼的用眼看,其余的 grep -i xxx.log |less
|
 |
83
iguess 7 天前
第一阶段: 看日志
|
 |
84
bli22ard 7 天前
@whoami9426 #40 这个是不是 javaagent 实现的?
|
|
85
whoami9426 7 天前
@bli22ard 基于 aop 实现的, aop + git blame + webhook
|
 |
86
spinlock 7 天前
代码注释 二分查找
|

 |
88
Alliot 7 天前
总的来说就是可观测性那一套 Metrics+Log+tracing.
用得多的就是 Promethues 全家桶,ELK 那套日志, 加 APM. 往细节上, 除去系统性能指标那些,还加上了应用/业务指标的监控。 网关层面的状态码监控。 再加上数据库慢 SQL 之类的监控。 最后还有就是波测,SaaS 多地监控。 |
|
89
bli22ard 7 天前
@whoami9426 #85 git blame 只有在编译阶段才有吧, 难道你们每次编译生成了一个代码行和 git blame 的对应关系,出现异常 ,用堆栈类+行号 取找 git blame 的信息,然后生成通知信息?
|
|
90
whoami9426 7 天前
@bli22ard #89 是直接请求 git 平台的 git blame api , 根据仓库,分支 实时读取的最新的代码
|
|
91
bli22ard 7 天前
@whoami9426 #90 厉害了。
|

 |
94
quzard 6 天前 via iPhone
完全用 SLS 来排查和运维
|

 |
96
zcl0621 6 天前 @JoeDH kafka ,redis ,pg ,clickhouse 全部拆出去部署;需要修改 selfhosting 的脚本,compose 文件,还有几个 py 文件;以及手动去执行 kafka ,pg ,clickhouse 的初始化文件;其他那些组件都跑在一台 16c 还是 32c 的机器上(目前离职一段时间了,我不太记得了);还需要调整 container 的数量。总之 selfhosting 的坑贼多,文档也很少,只能自己摸索。
|
 |
97
wogogoing 6 天前 via iPhone
|
 |
98
jukanntenn 6 天前 我们公司是
try: ... except: pass 没有报错就没有 bug |
 |
99
kid1412621 6 天前 via iPhone
@proxychains #73 加下 —no-pager😂
|
|
100
kid1412621 6 天前 via iPhone
|